Latency - How long does a single operation of the smallest fundamental unit take to complete.
Throughput - How many bytes of data per second can we read or write
Parallel scaling - When several requests are issued at the same, or nearly the same time, how are latency and throughput affected.
Resilience to failure of storage components - How many and which types of storage hardware failures can be tolerated without the system availability being interrupted and how is performance affected.
Resilience to failure of network components - If a network is partitioned or fails, does the storage system remain consistent and how are partially complete operations handled
Semantics - What capabilities are offered to clients? Can existing files be re-written? Are there folders? Is random access possible? How are files locked and shared? Are there any transactional semantics?
To prevent the loss of availability of data, the use of RAID
(Redundant Array of Inexpensive Disks) allows for redundant copies of
data to be stored.
Common RAID levels are:
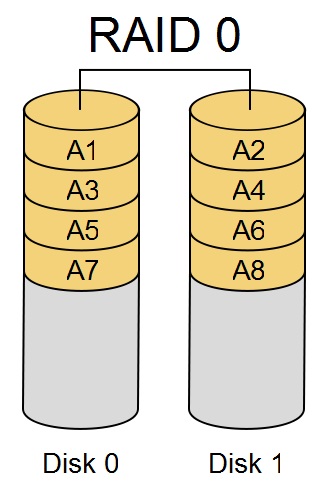
RAID 0 - splits data across disks. Increases disk space and
provides no redundancy. 2 or more disks are needed.
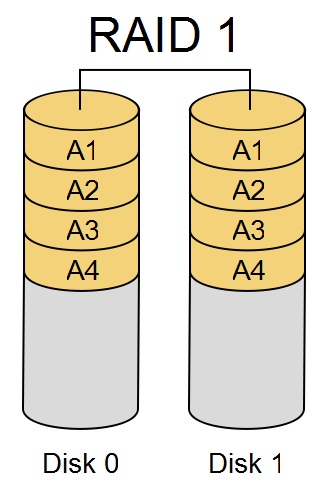
RAID 1 - creates an exact copy of data on two or more disks.
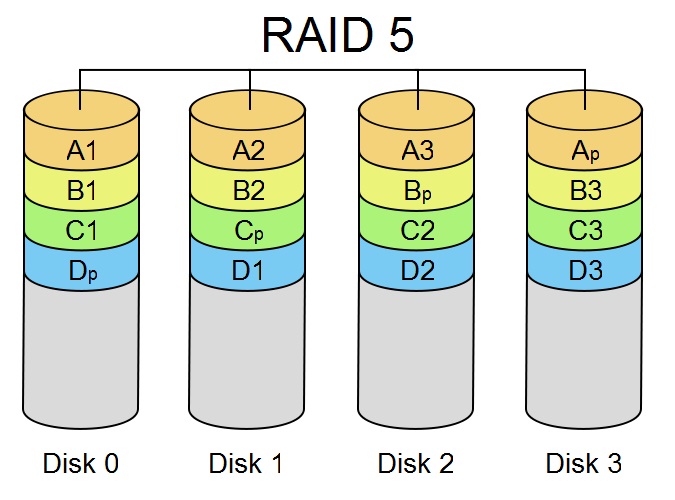
RAID 5/6 - splits data across disks. Uses one or more disks for
parity. This allows 1-K out of N disks to fail and allow the data
of any lost disk to be recovered. 3 or more disks are needed.
Complete hardware implementation - a disk controller or expansion
card implements RAID. Several disks are connected to this
controller and it is presented to the operating system as a single
storage device. Often have reliability guarantees.
Partial hardware implementation - Same as the complete hardware
implementation, except parity calculations, and buffering are
delegated to the host CPU and memory. Don’t often have reliability
guarantees.
Software implementation - The operating system itself manages
several disks and presents to the file-system layer a single
storage device.
How files and folders are implemented in a storage medium can greatly
depend upon the physical characteristics and capabilities of that
medium.
For example, on tape-drives, CD/DVD/Blu-Ray, or write-once media,
files and folders are stored contiguously with no fragmentation. All
of the information about the filesystem can be held in a TOC (Table
Of Contents).
For filesystems with files that have a finite lifetime, such as on
flash media, hard disks, SSDs, and others, the layout of files and
folders must be maintained in a more complex way.
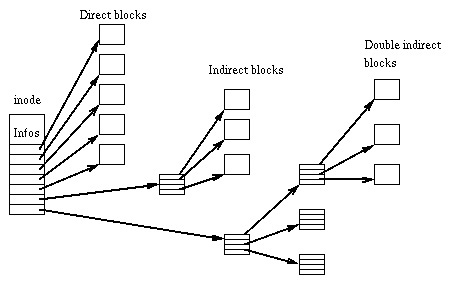
Among these more advanced methods are linked lists and i-nodes.
To manage free-space, objects like bit-maps and linked lists are
possibilities.
To improve the performance of a filesystem, and to make disk
scheduling algorithms more realizable, most operating systems
implement some kind of block cache.
The block cache allows for read-ahead and write-behind. It also
allows for lower latency I/O operations.
With a block cache, the write() system call for instance only needs
to complete modifications to the cache before returning. The
operating system can complete the operation on disk in a background
thread.
Without this cache, the system call would not be able to return until
the write had been committed to disk.
Important parameters of any block cache are:
The size of the cache in physical memory
The delay before committing ’dirty’ items in the cache to disk
The larger the cache, the better the filesystem will likely perform,
but this can come at the cost of available memory for programs.
The larger the delay before writing items to the disk, the better the
disk allocation and scheduling decisions the operating system can
make.
The shorter the delay before writing to disk, the greater the
guarantee in the presence of failure that modifications will be
persisted to disk.
Aside from files and folders there are other things like named pipes,
domain sockets, symbolic and hard links that need to be handled by
the filesystem.
Rather than have the semantics of these implemented in each
filesystem implementation, many OS architectures include a virtual
filesystem or VFS.
The VFS stands between the OS kernel and the filesystem
implementation.
In some VFS implementations it is possible to stack filesystems on
top of each other.
A great example of this in Linux is UMSDOS: the base VFAT filesystem
does not have support for users, groups, security or extended
attributes. By creating special files on VFAT and then hiding them,
UMSDOS can adapt VFAT to be a UNIX-like filesystem
Another great example of this is UnionFS. It allows two filesystems
to be transparently overlaid.